
Pandas is the best python module for manipulating dataframes. It has many useful functions. The pandas factorize() method is one of them. Do you what it does? It finds out the uniques values in the array and returns it as a numerical value.
The syntax for the pandas method is below.
pandas.factorize(values, sort=False, na_sentinel=- 1, size_hint=None)Below is an explanation of each of the parameters.
values: One Dimensional ndarray.
sort: Allows you to sort the values of the input array.
na_sentinel: Useful when you have NaN values in the array. The default value is -1. Missing Values are marked as ‘not found’.
These are mostly used parameters. You can read panda.factorize() to know more about the other parameters.
Examples for the Pandas Factorize Pandas Method
Example 1: Simple Use of Factorize() Method.
In this example, I will create a list of strings and then use the factorize method to convert it to a numerical value.
Let’s create a Simple array with duplicates values in it.
array_list = ["a","a","c","b","b","d","c"]After that pass, it to the factorize() method to find the array of unique values and its labels. Run the following code.
lables,uniques = pd.factorize(array_list)If you printout the values you will get the following output.

Example 2: Sorting the unique values and shuffling the codes.
If you also pass the sort=True in the pandas.factorize() method. Then the values will be sorted and it’s labeled will be shuffled.
Execute the code below.
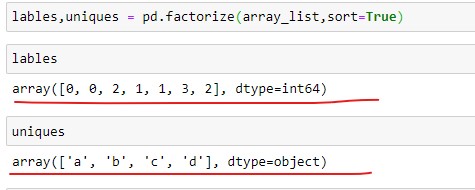
lables,uniques = pd.factorize(array_list,sort=True)When you printout the labels and uniques you will get the following output.
Example 3: Handline with the Missing Values.
Sometimes you have also missing values inside the data. The pandas.factorize() method will eliminate it. Until you have not defined an extra argument that is na_sentinel =None.
Let’s look at the code of cases.
Case 1: Eliminating Missing Values.
Let’s create a list of the missing values. It can be None or NaN.
Then if you pass the list to the pandas.factorize() method. You will get the uniques without any missing values.
array_list = ["a","a","c","b",np.nan,"d",None]
lables,uniques = pd.factorize(array_list)Output

You can see in the label output the default value of np. nan and None are set to -1. It’s due to the default value of na_sentinel. In the next case, I will show you how to set any negative value using it instead of -1.
Case 2: Eliminating Missing Values with custom na_sentinel value.
Suppose I want to use -18 instead of -1 in missing values then I will pass the na_sentinel = -18 inside the factorize() method.
lables,uniques = pd.factorize(array_list,na_sentinel= -18)Output

END NOTES
That’s all for now. These are the methods and cases for implementing the pandas factorize() method. This method is very useful in grouping and converting values to numerical data.
I hope you have followed all the examples for getting deep knowledge about it. Even if you have other queries then you can contact us.
Source:
Offical Pandas Factorize() Documentation

Join our list
Subscribe to our mailing list and get interesting stuff and updates to your email inbox.
